Create a new Kedro project¶
There are several ways to create a new Kedro project. This page explains the flow to create a basic project using kedro new to output a project directory containing the basic files and subdirectories that make up a Kedro project.
You can also create a new Kedro project with a starter that adds code for a common project use case. Starters are explained separately and the spaceflights tutorial illustrates their use.
Introducing kedro new¶
To create a basic Kedro project containing the default code needed to set up your own nodes and pipelines, navigate to your preferred directory and type:
kedro new
Project name¶
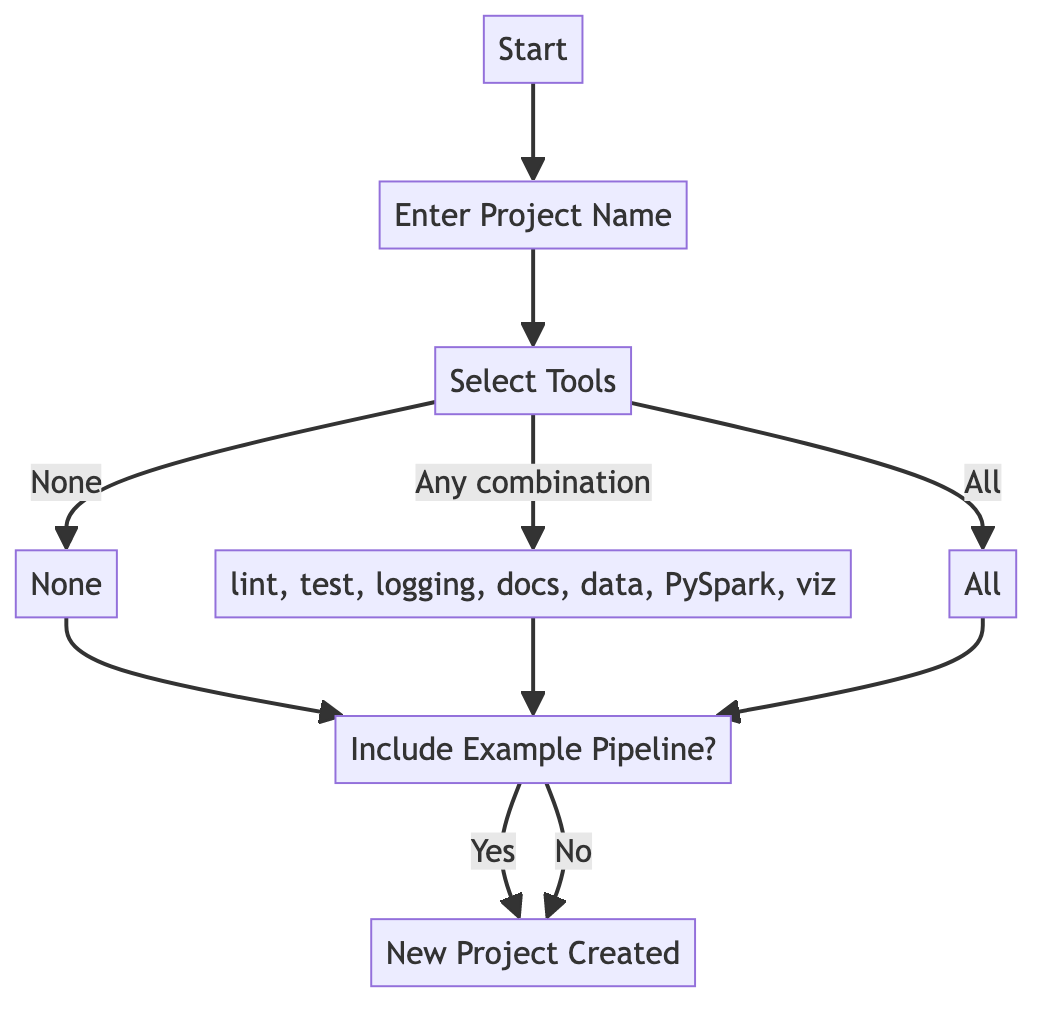
The command line interface (CLI) first asks for a name for the project. This is the human-readable name, and it may contain alphanumeric symbols, spaces, underscores, and hyphens. It must be at least two characters long.
It’s best to keep the name simple because the choice is set as the value of project_name and is also used to generate the folder and package names for the project automatically. For example, if you enter “Get Started”, the folder for the project (repo_name) is automatically set to be get-started, and the Python package name (python_package) for the project is set to be get_started.
Description |
Setting |
Example |
|---|---|---|
A human-readable name for the new project |
|
|
Local directory to store the project |
|
|
The Python package name for the project (short, all-lowercase) |
|
|
Project tools¶
Next, the CLI asks which tools you’d like to include in the project:
Tools
1) Lint: Basic linting with ruff
2) Test: Basic testing with pytest
3) Log: Additional, environment-specific logging options
4) Docs: A Sphinx documentation setup
5) Data Folder: A folder structure for data management
6) PySpark: Configuration for working with PySpark
7) Kedro-Viz: Kedro's native visualisation tool
Which tools would you like to include in your project? [1-7/1,3/all/none]:
(none):
The options are described in more detail in the documentation about the new project tools.
Select the tools by number, or all or follow the default to add none.
Project examples¶
The CLI offers the option to include starter example code in the project:
Would you like to include an example pipeline? :
(no):
If you say yes, the example code included depends upon your previous choice of tools, as follows:
Default spaceflights starter (
spaceflights-pandas): Added if you selected any combination of linting, testing, custom logging, documentation, and data structure, unless you also selected PySpark or Kedro Viz.PySpark spaceflights starter (
spaceflights-pyspark): Added if you selected PySpark with any other tools, unless you also selected Kedro Viz.Kedro Viz spaceflights starter (
spaceflights-pandas-viz): Added if Kedro Viz was one of your tools choices, unless you also selected PySpark.Full feature spaceflights starter (
spaceflights-pyspark-viz): Added if you selected all available tools, including PySpark and Kedro Viz.
Each starter example is tailored to demonstrate the capabilities and integrations of the selected tools, offering a practical insight into how they can be utilised in your project.
Quickstart examples¶
To create a default Kedro project called
My-Projectwith no tools and no example code:
kedro new ⮐
My-Project ⮐
none ⮐
no ⮐
You can also enter this in a single line as follows:
kedro new --name=My-Project --tools=none --example=n
To create a spaceflights project called
spaceflightswith Kedro Viz features and example code:
kedro new ⮐
spaceflights ⮐
7 ⮐
yes ⮐
You can also enter this in a single line as follows:
kedro new --name=spaceflights --tools=viz --example=y
To create a project, called
testprojectcontaining linting, documentation, and PySpark, but no example code:
kedro new ⮐
testproject ⮐
1,4,6 ⮐
no ⮐
You can also enter this in a single line as follows:
kedro new --name=testproject --tools=lint,docs,pyspark --example=n
Telemetry consent¶
The --telemetry flag offers the option to register consent to have user analytics collected in the moment of the creation of the project. This option bypasses the prompt to collect analytics that would otherwise appear on the moment the kedro command is invoked for the first time inside the project. In case the --telemetry flag is not used, the user will be prompted to accept or reject analytics collection as usual.
When creating your new Kedro project, use the values yes or no to register consent to have user analytics collected for this specific project. Selecting yes means you consent to your data being collected, whereas no means you do not consent and no data will be collected.
Run the new project¶
Whichever options you selected for tools and example code, once kedro new has completed, the next step is to navigate to the project folder (cd <project-name>) and install dependencies with pip as follows:
pip install -r requirements.txt
Now run the project:
kedro run
Note
The first time you type a kedro command in a new project, you will be asked whether you wish to opt into usage analytics. Your decision is recorded in the .telemetry file so that subsequent calls to kedro in this project do not ask this question again.
Visualise a Kedro project¶
This section swiftly introduces project visualisation using Kedro-Viz. See the Kedro-Viz documentation for more detail.
The Kedro-Viz package needs to be installed into your virtual environment separately as it is not part of the standard Kedro installation:
pip install kedro-viz
To start Kedro-Viz, navigate to the project folder (cd <project-name>) and enter the following in your terminal:
kedro viz run
This command automatically opens a browser tab to serve the visualisation at http://127.0.0.1:4141/.
To exit the visualisation, close the browser tab. To regain control of the terminal, enter ^+c on Mac or Ctrl+c on Windows or Linux machines.
Where next?¶
You have completed the section on Kedro project creation for new users. Here are some useful resources to learn more:
Understand more about Kedro: The following page explains the fundamental Kedro concepts.
Learn hands-on: If you prefer to learn hands-on, move on to the spaceflights tutorial. The tutorial illustrates how to set up a working project, add dependencies, create nodes, register pipelines, set up the Data Catalog, add documentation, and package the project.
How-to guide for notebook users: The documentation section following the tutorial explains how to combine Kedro with a Jupyter notebook.
If you’ve worked through the documentation listed and are unsure where to go next, review the Kedro repositories on GitHub and Kedro’s Slack channels.
Flowchart of general choice of tools¶
Here is a flowchart to help guide your choice of tools and examples you can select: